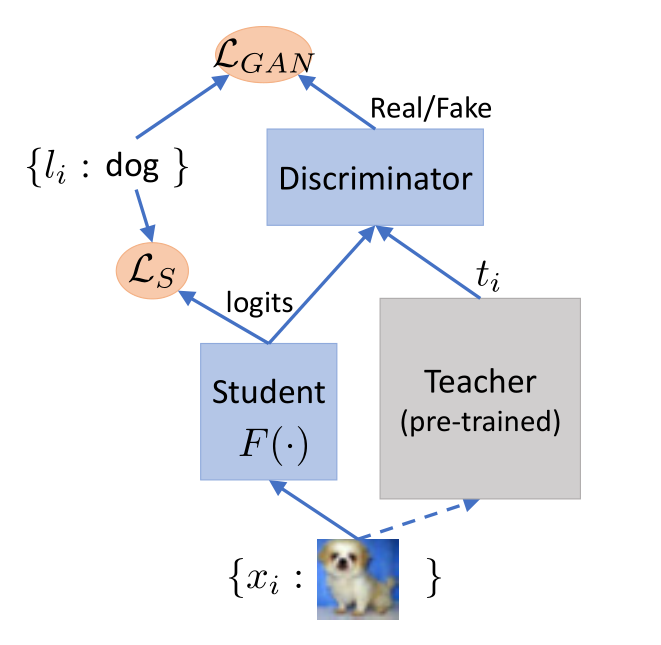
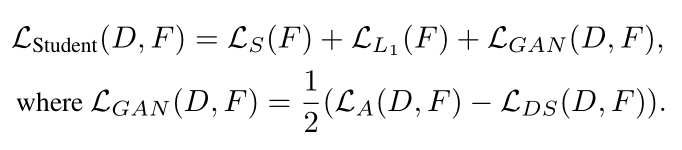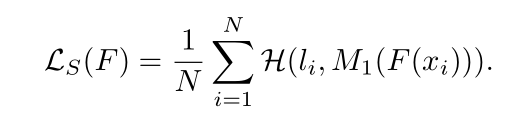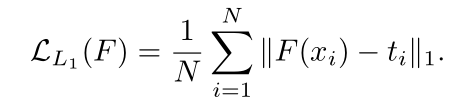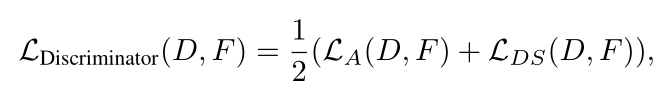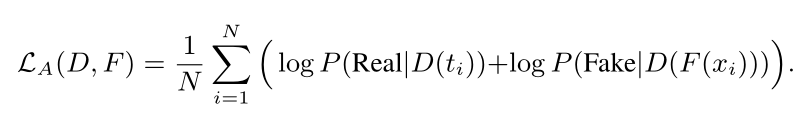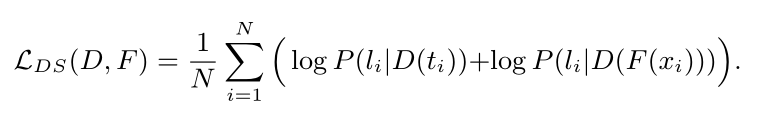Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adversarial Networks Posted on 2020-04-03 | In Papers 利用条件对抗网络来学习损失函数,从而将知识从teacher转移到student。 网络介绍网络结构: 总体损失: LS即普通分类损失函数: 由于在discriminator训练中容易忽略条件向量,故在训练student网络中采用实例对齐方式(教师网络与学生网络输出之间实例对齐),即:其中,F(·)为学生网络,t_i为输入图像经过预训练教师网络后生成对数向量。 discriminator损失: